filmov
tv
databricks python multiprocessing
0:11:47
Pyspark Scenarios 16: Convert pyspark string to date format issue dd-mm-yy old format #pyspark
0:22:29
Large Scale Data Loading and Data Preprocessing with Ray
0:20:03
[RTSS 2020] DAG Scheduling and Analysis on Multiprocessor Systems
1:32:54
Calcolo parallelo e distribuito in Python 02 - Comunicazioni intra processi e Ray
0:20:19
How to use Python SDK for Azure Automation
0:18:15
Pandas DataFrame: turbo charge with PySpark on 12 CPU threads on single node
0:23:30
Rehan Durrani - How to maximally parallelize the entire pandas API | PyData Global 2022
0:34:51
Ray: A System for High-performance, Distributed Python Applications - Dean Wampler
0:07:56
Pyspark Scenarios 9 : How to get Individual column wise null records count #pyspark #databricks
0:45:59
Parallelizing Existing R Packages with SparkR: Spark Summit East talk by Hossein Falaki
0:39:50
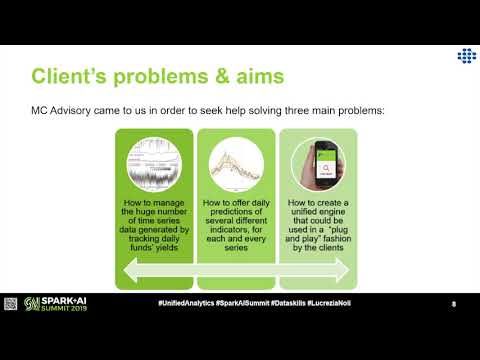
Working with 1 Million Time Series a Day: How to Scale Up a Predictive Analytics Model Switching
0:26:34
Assimilate-Python
0:26:10
Predicting Optimal Parallelism for Data Analytics
0:45:05
DynamoDB with Python (Latest)
0:06:56
Python Tutorial 1: Python Introduction, Python Basics, Python for pyspark, #PythonTutorial In Telugu
0:02:43
Mastering Python - Understanding Map Reduce Libraries - 02 Preparing Data Sets
0:39:13
Alessandro Amici - Meet dask and distributed: the unsung heroes of Python scientific data ecosystem
1:55:37
Efficient use of Python on the clusters
0:23:33
Fast Scheduling using Ray's Python API (0.8) by Edward Oakes
0:04:35
Multi node training with PyTorch DDP, torch.distributed.launch, torchrun and mpirun
0:53:32
Holden Karau: A brief introduction to Distributed Computing with PySpark
0:28:20
Productionizing Real-time Serving With MLflow
1:31:33
Data Science DC May 2022 Meetup: Scaling and Distributing Python & ML Applications with Ray
0:12:28
Pyspark Scenarios 3 : how to skip first few rows from data file in pyspark
Назад
Вперёд
join shbcf.ru
 0:11:47
0:11:47
 0:22:29
0:22:29
![[RTSS 2020] DAG](https://i.ytimg.com/vi/DriyJdDGtNc/hqdefault.jpg) 0:20:03
0:20:03
 1:32:54
1:32:54
 0:20:19
0:20:19
 0:18:15
0:18:15
 0:23:30
0:23:30
 0:34:51
0:34:51
 0:07:56
0:07:56
 0:45:59
0:45:59
 0:39:50
0:39:50
 0:26:34
0:26:34
 0:26:10
0:26:10
 0:45:05
0:45:05
 0:06:56
0:06:56
 0:02:43
0:02:43
 0:39:13
0:39:13
 1:55:37
1:55:37
 0:23:33
0:23:33
 0:04:35
0:04:35
 0:53:32
0:53:32
 0:28:20
0:28:20
 1:31:33
1:31:33
 0:12:28
0:12:28